Today we are very excited to announce that Amazon Aurora Serverless v2 is generally available for both Aurora PostgreSQL and MySQL. Aurora Serverless is an on-demand, auto-scaling configuration for Amazon Aurora that allows your database to scale capacity up or down based on your application’s needs.
Amazon Aurora is a MySQL- and PostgreSQL-compatible relational database built for the cloud. It is fully managed by Amazon Relational Database Service (RDS), which automates time-consuming administrative tasks, such as hardware provisioning, database setup, patches, and backups.
One of the key features of Amazon Aurora is the separation of compute and storage. As a result, they scale independently. Amazon Aurora storage automatically scales as the amount of data in your database increases. For example, you can store lots of data, and if one day you decide to drop most of the data, the storage provisioned adjusts.
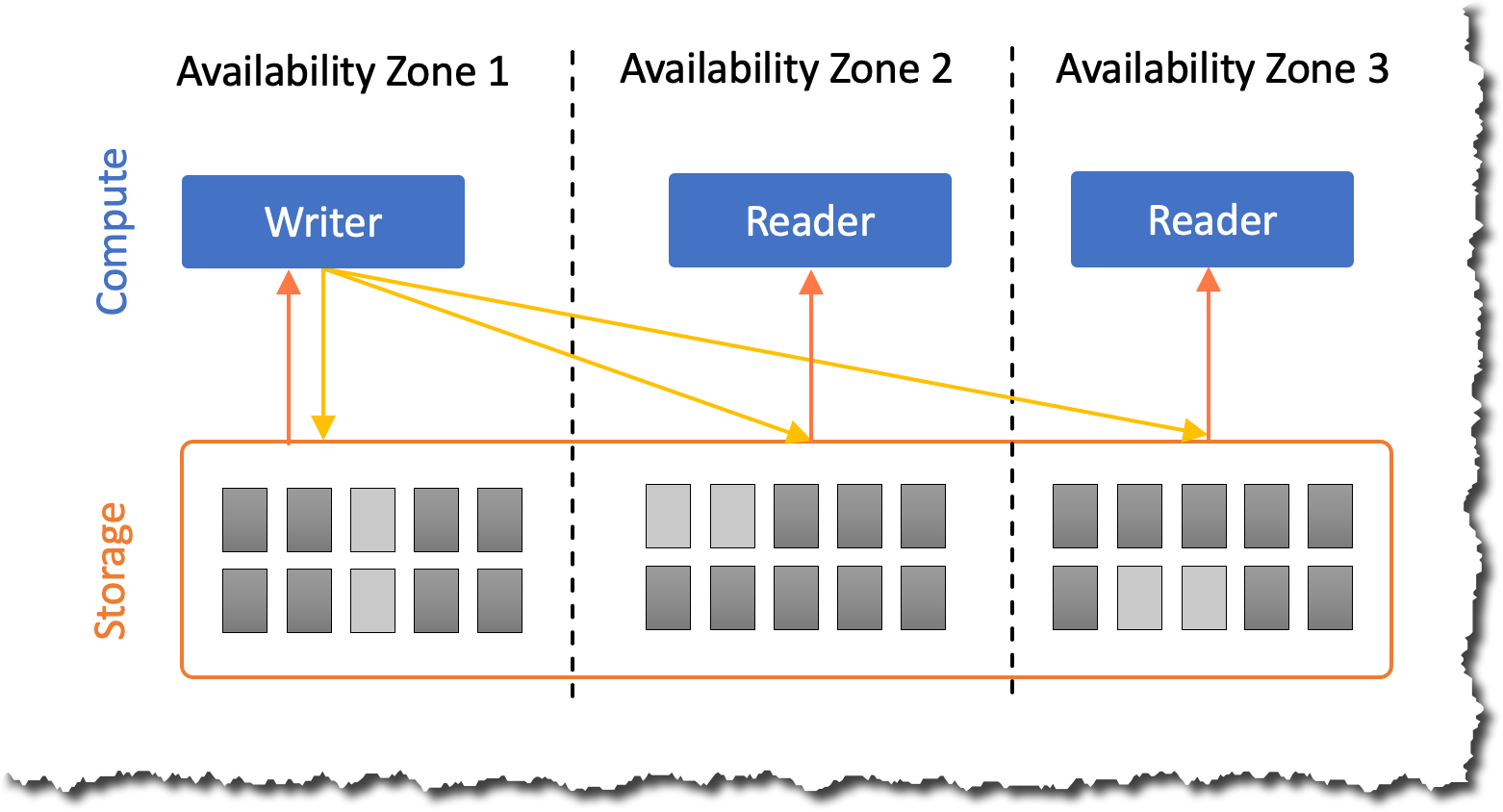
However, many customers said that they need the same flexibility in the compute layer of Amazon Aurora since most database workloads don’t need a constant amount of compute. Workloads can be spiky, infrequent, or have predictable spikes over a period of time.
To serve these kinds of workloads, you need to provision for the peak capacity you expect your database will need. However, this approach is expensive as database workloads rarely run at peak capacity. To provision the right amount of compute, you need to continuously monitor the database capacity consumption and scale up resources if consumption is high. However, this requires expertise and often incurs downtime.
To solve this problem, in 2018, we launched the first version of Amazon Aurora Serverless. Since its launch, thousands of customers have used Amazon Aurora Serverless as a cost-effective option for infrequent, intermittent, and unpredictable workloads.
Today, we are making the next version of Amazon Aurora Serverless generally available, which enables customers to run even the most demanding workload on serverless with instant and nondisruptive scaling, fine-grained capacity adjustments, and additional functionality, including read replicas, Multi-AZ deployments, and Amazon Aurora Global Database.
Aurora Serverless v2 is launching with the latest major versions available on Amazon Aurora. Versions supported: Aurora PostgreSQL-compatible edition with PostgreSQL 13 and Aurora MySQL-compatible edition with MySQL 8.0.
Main features of Aurora Serverless v2
Aurora Serverless v2 enables you to scale your database to hundreds of thousands of transactions per second and cost-effectively manage the most demanding workloads. It scales database capacity in fine-grained increments to closely match the needs of your workload without disrupting connections or transactions. In addition, you pay only for the exact capacity you consume, and you can save up to 90 percent compared to provisioning for peak load.
If you have an existing Amazon Aurora cluster, you can create an Aurora Serverless v2 instance within the same cluster. This way, you’ll have a mixed configuration cluster where both provisioned and Aurora Serverless v2 instances can coexist within the same cluster.
It supports the full breadth of Amazon Aurora features. For example, you can create up to 15 Amazon Aurora read replicas deployed across multiple Availability Zones. Any number of these read replicas can be Aurora Serverless v2 instances and can be used as failover targets for high availability or for scaling read operations.
Similarly, with Global Database, you can assign any of the instances to be Aurora Serverless v2 and only pay for minimum capacity when idling. These instances in secondary Regions can also scale independently to support varying workloads across different Regions. Check out the Amazon Aurora user guide for a comprehensive list of features.
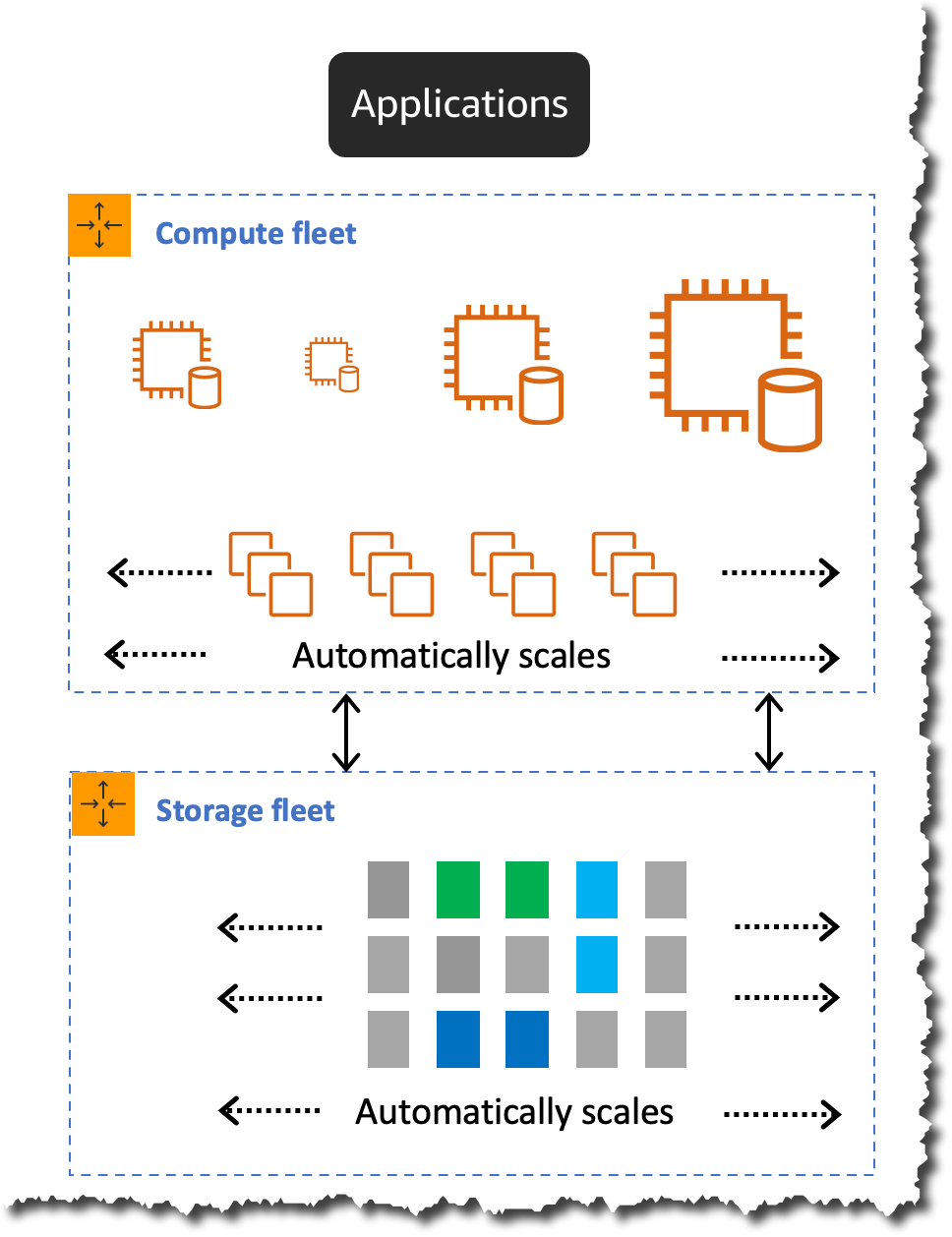
How Aurora Serverless v2 scaling works
Aurora Serverless v2 scales instantly and nondisruptively by growing the capacity of the underlying instance in place by adding more CPU and memory resources. This technique allows for the underlying instance to increase and decrease capacity in place without failing over to a new instance for scaling.
For scaling down, Aurora Serverless v2 takes a more conservative approach. It scales down in steps until it reaches the required capacity needed for the workload. Scaling down too quickly can prematurely evict cached pages and decrease the buffer pool, which may affect the performance.
Aurora Serverless capacity is measured in Aurora capacity units (ACUs). Each ACU is a combination of approximately 2 gibibytes (GiB) of memory, corresponding CPU, and networking. With Aurora Serverless v2, your starting capacity can be as small as 0.5 ACU, and the maximum capacity supported is 128 ACU. In addition, it supports fine-grained increments as small as 0.5 ACU which allows your database capacity to closely match the workload needs.
Aurora Serverless v2 scaling in action
To show Aurora Serverless v2 in action, we are going to simulate a flash sale. Imagine that you run an e-commerce site. You run a marketing campaign where customers can purchase items 50 percent off for a limited amount of time. You are expecting a spike in traffic on your site for the duration of the sale.
When you use a traditional database, if you run those marketing campaigns regularly, you need to provision for the peak load you expect. Or, if you run them now and then, you need to reconfigure your database for the expected peak of traffic during the sale. In both cases, you are limited to your assumption of the capacity you need. What happens if you have more sales than you expected? If your database cannot keep up with the demand, it may cause service degradation. Or when your marketing campaign doesn’t produce the sales you expected? You are unnecessarily paying for capacity you don’t need.
For this demo, we use Aurora Serverless v2 as the transactional database. An AWS Lambda function is used to call the database and process orders during the sale event for the e-commerce site. The Lambda function and the database are in the same Amazon Virtual Private Cloud (VPC), and the function connects directly to the database to perform all the operations.
To simulate the traffic of a flash sale, we will use an open-source load testing framework called Artillery. It will allow us to generate varying load by invoking multiple Lambda functions. For example, we can start with a small load and then increase it rapidly to observe how the database capacity adjusts based on the workload. This Artillery load test runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance inside the same VPC.
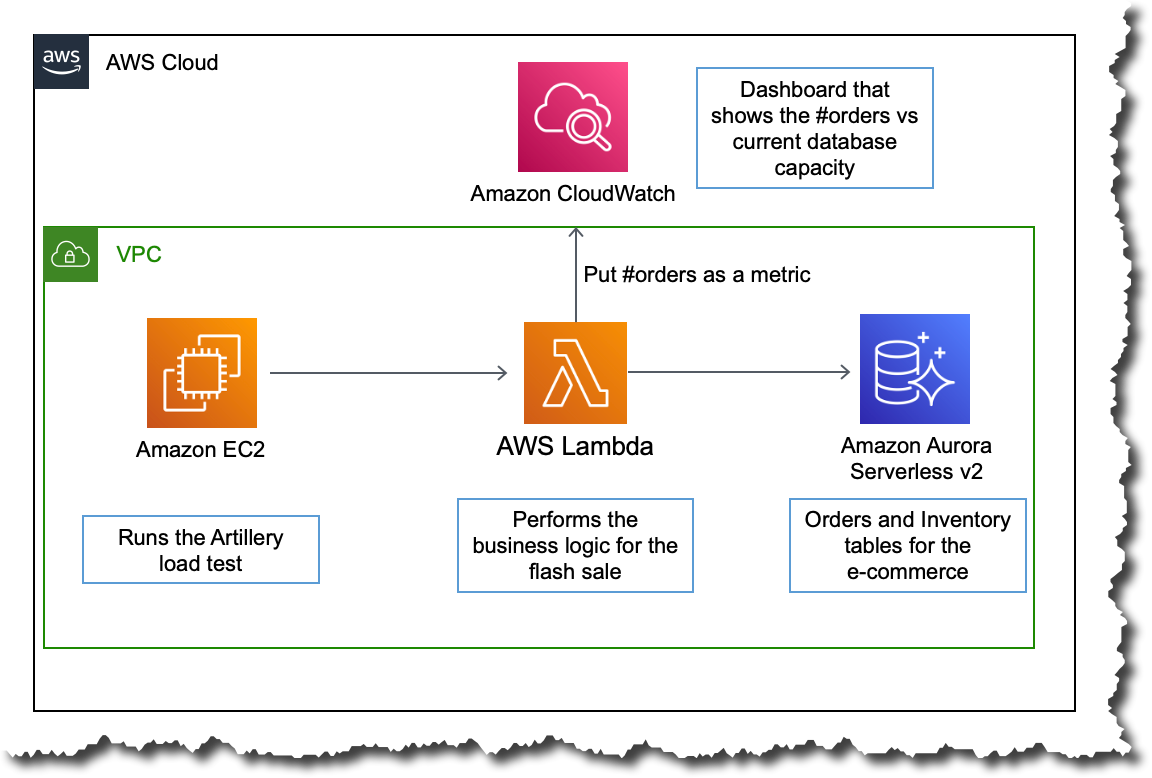
The following Amazon CloudWatch dashboard shows how the database capacity behaves when the order count increases. The dashboard shows the orders placed in blue and the current database capacity in orange.
At the beginning of the sale, the Aurora Serverless v2 database starts with a capacity of 5 ACUs, which was the minimum database capacity configured. For the first few minutes, the orders increase, but the database capacity doesn’t increase right away. The database can handle the load with the starting provisioned capacity.
However, around the time 15:55, the number of orders spikes to 12,000. As a result, the database increases the capacity to 14 ACUs. The database capacity increases in milliseconds, adjusting exactly to the load.
The number of orders placed stays up for some seconds, and then it goes dramatically down by 15:58. However, the database capacity doesn’t adjust exactly to the drop in traffic. Instead, it decreases in steps until it reaches 5 ACUs. The scaling down is done more conservatively to avoid prematurely evicting cached pages and affecting performance. This is done to prevent any unnecessary latency to spiky workloads, and also so the caches and buffer pools are not aggressively purged.

Get started with Aurora Serverless v2 with an existing Amazon Aurora cluster
If you already have an Amazon Aurora cluster and you want to try Aurora Serverless v2, the fastest way to get started is by using mixed configuration clusters that contain both serverless and provisioned instances. Start by adding a new reader into the existing cluster. Configure the reader instance to be of the type Serverless v2.
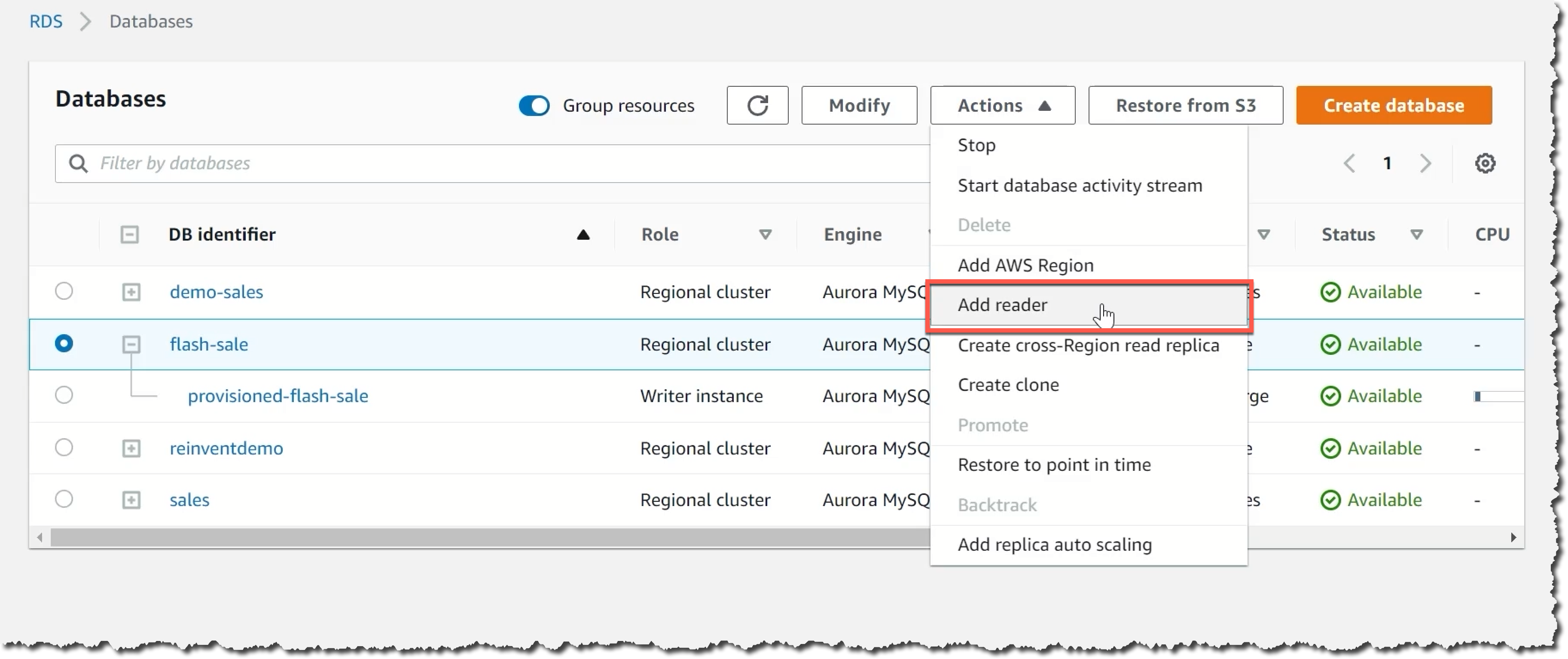
Test the new serverless instance with your workload. Once you have confirmation that it works as expected, you can start a failover to the serverless instance, which will take less than 30 seconds to finish. This option provides a minimal downtime experience to get started with Aurora Serverless v2.

How to create a new Aurora Serverless v2 database
To get started with Aurora Serverless v2, create a new database from the RDS console. The first step is to pick the engine type: Amazon Aurora. Then, pick which database engine you want it to be compatible with: MySQL or PostgreSQL. Open the filters under Engine version and select the filter Show versions that support Serverless v2. Then, you see that the Available versions dropdown list only shows options that are supported by Aurora Serverless v2.

Next, you need to set up the database. Specify credential settings with a username and password for the administrator of the database.

Then, configure the instance for the database. You need to select what kind of instance class you want. This allocates the computational, network, and memory capacity for the database instance. Select Serverless.
Then, you need to define the capacity range. Aurora Serverless v2 capacity scales up and down within the minimum and maximum configuration. Here you can specify the minimum and maximum database capacity for your workload. The minimum capacity you can specify is 0.5 ACUs, and the maximum is 128 ACUs. For more information on Aurora Serverless v2 capacity units, see the Instant autoscaling documentation.

Next, configure connectivity by creating a new VPC and security group or use the default. Finally, select Create database.

Creating the database takes a couple of minutes. You know your database is ready when the status switches to Available.
You will find the connection details for the database on the database page. The endpoint and the port, combined with the user name and password for the administrator, are all you need to connect to your new Aurora Serverless v2 database.

Available Now!
Aurora Serverless v2 is available now in US East (Ohio), US East (N. Virginia), US West (N. California), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo).
Visit the Amazon Aurora Serverless v2 page for more information about this launch.
– Marcia
from AWS News Blog https://aws.amazon.com/blogs/aws/amazon-aurora-serverless-v2-is-generally-available-instant-scaling-for-demanding-workloads/