Last year before re:Invent, we introduced the public preview of AWS Distro for OpenTelemetry, a secure distribution of the OpenTelemetry project supported by AWS. OpenTelemetry provides tools, APIs, and SDKs to instrument, generate, collect, and export telemetry data to better understand the behavior and the performance of your applications. Yesterday, upstream OpenTelemetry announced tracing stability milestone for its components. Today, I am happy to share that support for traces is now generally available in AWS Distro for OpenTelemetry.
Using OpenTelemetry, you can instrument your applications just once and then send traces to multiple monitoring solutions.
You can use AWS Distro for OpenTelemetry to instrument your applications running on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (EKS), and AWS Lambda, as well as on premises. Containers running on AWS Fargate and orchestrated via either ECS or EKS are also supported.
You can send tracing data collected by AWS Distro for OpenTelemetry to AWS X-Ray, as well as partner destinations such as:
- AppDynamics, Dynatrace, Grafana, Honeycomb, Lightstep, NewRelic, and SumoLogic – which support OpenTelemetry Protocol (OTLP) exporters natively.
- Datadog, Logz.io, Splunk – which have their own exporters.
You can use auto-instrumentation agents to collect traces without changing your code. Auto-instrumentation is available today for Java and Python applications. Auto-instrumentation support for Python currently only covers the AWS SDK. You can instrument your applications using other programming languages (such as Go, Node.js, and .NET) with the OpenTelemetry SDKs.
Let’s see how this works in practice for a Java application.
Visualizing Traces for a Java Application Using Auto-Instrumentation
I create a simple Java application that shows the list of my Amazon Simple Storage Service (Amazon S3) buckets and my Amazon DynamoDB tables:
package com.example.myapp;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.*;
import software.amazon.awssdk.services.dynamodb.model.DynamoDbException;
import software.amazon.awssdk.services.dynamodb.model.ListTablesResponse;
import software.amazon.awssdk.services.dynamodb.model.ListTablesRequest;
import software.amazon.awssdk.services.dynamodb.DynamoDbClient;
import java.util.List;
/**
* Hello world!
*
*/
public class App {
public static void listAllTables(DynamoDbClient ddb) {
System.out.println("DynamoDB Tables:");
boolean moreTables = true;
String lastName = null;
while (moreTables) {
try {
ListTablesResponse response = null;
if (lastName == null) {
ListTablesRequest request = ListTablesRequest.builder().build();
response = ddb.listTables(request);
} else {
ListTablesRequest request = ListTablesRequest.builder().exclusiveStartTableName(lastName).build();
response = ddb.listTables(request);
}
List<String> tableNames = response.tableNames();
if (tableNames.size() > 0) {
for (String curName : tableNames) {
System.out.format("* %s\n", curName);
}
} else {
System.out.println("No tables found!");
System.exit(0);
}
lastName = response.lastEvaluatedTableName();
if (lastName == null) {
moreTables = false;
}
} catch (DynamoDbException e) {
System.err.println(e.getMessage());
System.exit(1);
}
}
System.out.println("Done!\n");
}
public static void listAllBuckets(S3Client s3) {
System.out.println("S3 Buckets:");
ListBucketsRequest listBucketsRequest = ListBucketsRequest.builder().build();
ListBucketsResponse listBucketsResponse = s3.listBuckets(listBucketsRequest);
listBucketsResponse.buckets().stream().forEach(x -> System.out.format("* %s\n", x.name()));
System.out.println("Done!\n");
}
public static void listAllBucketsAndTables(S3Client s3, DynamoDbClient ddb) {
listAllBuckets(s3);
listAllTables(ddb);
}
public static void main(String[] args) {
Region region = Region.EU_WEST_1;
S3Client s3 = S3Client.builder().region(region).build();
DynamoDbClient ddb = DynamoDbClient.builder().region(region).build();
listAllBucketsAndTables(s3, ddb);
s3.close();
ddb.close();
}
}I package the application using Apache Maven. Here’s the Project Object Model (POM) file managing dependencies such as the AWS SDK for Java 2.x that I use to interact with S3 and DynamoDB:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<groupId>com.example.myapp</groupId>
<artifactId>myapp</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>myapp</name>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.17.38</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>dynamodb</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.example.myapp.App</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>I use Maven to create an executable Java Archive (JAR) file that includes all dependencies:
To run the application and get tracing data, I need two components:
- The AWS Distro for OpenTelemetry Auto-Instrumentation Agent for Java, a Java agent that can be attached to any Java 8+ application to capture telemetry from a number of popular libraries and frameworks, including the AWS SDK.
- The AWS Distro for OpenTelemetry Collector, an executable that can receive, process, and export telemetry data to monitoring destinations.
In one terminal, I run the AWS Distro for OpenTelemetry Collector using Docker:
The collector is now ready to receive traces and forward them to a monitoring platform. By default, the AWS Distro for OpenTelemetry Collector sends traces to AWS X-Ray. I can change the exporter or add more exporters by editing the collector configuration. For example, I can follow the documentation to configure OLTP exporters to send telemetry data using the OLTP protocol. In the documentation, I also find how to configure other partner destinations. [[ It would be great it we had a link for the partner section, I can find only links to a specific partner ]]
I download the latest version of the AWS Distro for OpenTelemetry Auto-Instrumentation Java Agent. Now, I run my application and use the agent to capture telemetry data without having to add any specific instrumentation the code. In the OTEL_RESOURCE_ATTRIBUTES environment variable I set a name and a namespace for the service: [[ Are service.name and service.namespace being used by X-Ray? I couldn’t find them in the service map ]]
As expected, I get the list of my S3 buckets globally and of the DynamoDB tables in the Region.
To generate more tracing data, I run the previous command a few times. Each time I run the application, telemetry data is collected by the agent and sent to the collector. The collector buffers the data and then sends it to the configured exporters. By default, it is sending traces to X-Ray.
Now, I look at the service map in the AWS X-Ray console to see my application’s interactions with other services:

And there they are! Without any change in the code, I see my application’s calls to the S3 and DynamoDB APIs. There were no errors, and all the circles are green. Inside the circles, I find the average latency of the invocations and the number of transactions per minute.
Adding Spans to a Java Application
The information automatically collected can be improved by providing more information with the traces. For example, I might have interactions with the same service in different parts of my application, and it would be useful to separate those interactions in the service map. In this way, if there is an error or high latency, I would know which part of my application is affected.
One way to do so is to use spans or segments. A span represents a group of logically related activities. For example, the listAllBucketsAndTables method is performing two operations, one with S3 and one with DynamoDB. I’d like to group them together in a span. The quickest way with OpenTelemetry is to add the @WithSpan annotation to the method. Because the result of a method usually depends on its arguments, I also use the @SpanAttribute annotation to describe which arguments in the method invocation should be automatically added as attributes to the span.
@WithSpan
public static void listAllBucketsAndTables(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb) {
System.out.println(title);
listAllBuckets(s3);
listAllTables(ddb);
}To be able to use the @WithSpan and @SpanAttribute annotations, I need to import them into the code and add the necessary OpenTelemetry dependencies to the POM. All these changes are based on the OpenTelemetry specifications and don’t depend on the actual implementation that I am using, or on the tool that I will use to visualize or analyze the telemetry data. I have only to make these changes once to instrument my application. Isn’t that great?
To better see how spans work, I create another method that is running the same operations in reverse order, first listing the DynamoDB tables, then the S3 buckets:
@WithSpan
public static void listTablesFirstAndThenBuckets(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb) {
System.out.println(title);
listAllTables(ddb);
listAllBuckets(s3);
}
The application is now running the two methods (listAllBucketsAndTables and listTablesFirstAndThenBuckets) one after the other. For simplicity, here’s the full code of the instrumented application:
package com.example.myapp;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.*;
import software.amazon.awssdk.services.dynamodb.model.DynamoDbException;
import software.amazon.awssdk.services.dynamodb.model.ListTablesResponse;
import software.amazon.awssdk.services.dynamodb.model.ListTablesRequest;
import software.amazon.awssdk.services.dynamodb.DynamoDbClient;
import java.util.List;
import io.opentelemetry.extension.annotations.SpanAttribute;
import io.opentelemetry.extension.annotations.WithSpan;
/**
* Hello world!
*
*/
public class App {
public static void listAllTables(DynamoDbClient ddb) {
System.out.println("DynamoDB Tables:");
boolean moreTables = true;
String lastName = null;
while (moreTables) {
try {
ListTablesResponse response = null;
if (lastName == null) {
ListTablesRequest request = ListTablesRequest.builder().build();
response = ddb.listTables(request);
} else {
ListTablesRequest request = ListTablesRequest.builder().exclusiveStartTableName(lastName).build();
response = ddb.listTables(request);
}
List<String> tableNames = response.tableNames();
if (tableNames.size() > 0) {
for (String curName : tableNames) {
System.out.format("* %s\n", curName);
}
} else {
System.out.println("No tables found!");
System.exit(0);
}
lastName = response.lastEvaluatedTableName();
if (lastName == null) {
moreTables = false;
}
} catch (DynamoDbException e) {
System.err.println(e.getMessage());
System.exit(1);
}
}
System.out.println("Done!\n");
}
public static void listAllBuckets(S3Client s3) {
System.out.println("S3 Buckets:");
ListBucketsRequest listBucketsRequest = ListBucketsRequest.builder().build();
ListBucketsResponse listBucketsResponse = s3.listBuckets(listBucketsRequest);
listBucketsResponse.buckets().stream().forEach(x -> System.out.format("* %s\n", x.name()));
System.out.println("Done!\n");
}
@WithSpan
public static void listAllBucketsAndTables(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb) {
System.out.println(title);
listAllBuckets(s3);
listAllTables(ddb);
}
@WithSpan
public static void listTablesFirstAndThenBuckets(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb) {
System.out.println(title);
listAllTables(ddb);
listAllBuckets(s3);
}
public static void main(String[] args) {
Region region = Region.EU_WEST_1;
S3Client s3 = S3Client.builder().region(region).build();
DynamoDbClient ddb = DynamoDbClient.builder().region(region).build();
listAllBucketsAndTables("My S3 buckets and DynamoDB tables", s3, ddb);
listTablesFirstAndThenBuckets("My DynamoDB tables first and then S3 bucket", s3, ddb);
s3.close();
ddb.close();
}
}And here’s the updated POM that includes the additional OpenTelemetry dependencies:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<groupId>com.example.myapp</groupId>
<artifactId>myapp</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>myapp</name>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.16.60</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>dynamodb</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-extension-annotations</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
<version>1.5.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.example.myapp.App</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>I compile my application with these changes and run it again a few times:
Now, let’s look at the X-Ray service map, computed using the additional information provided by those annotations.

Now I see the two methods and the other services they invoke. If there are errors or high latency, I can easily understand how the two methods are affected.
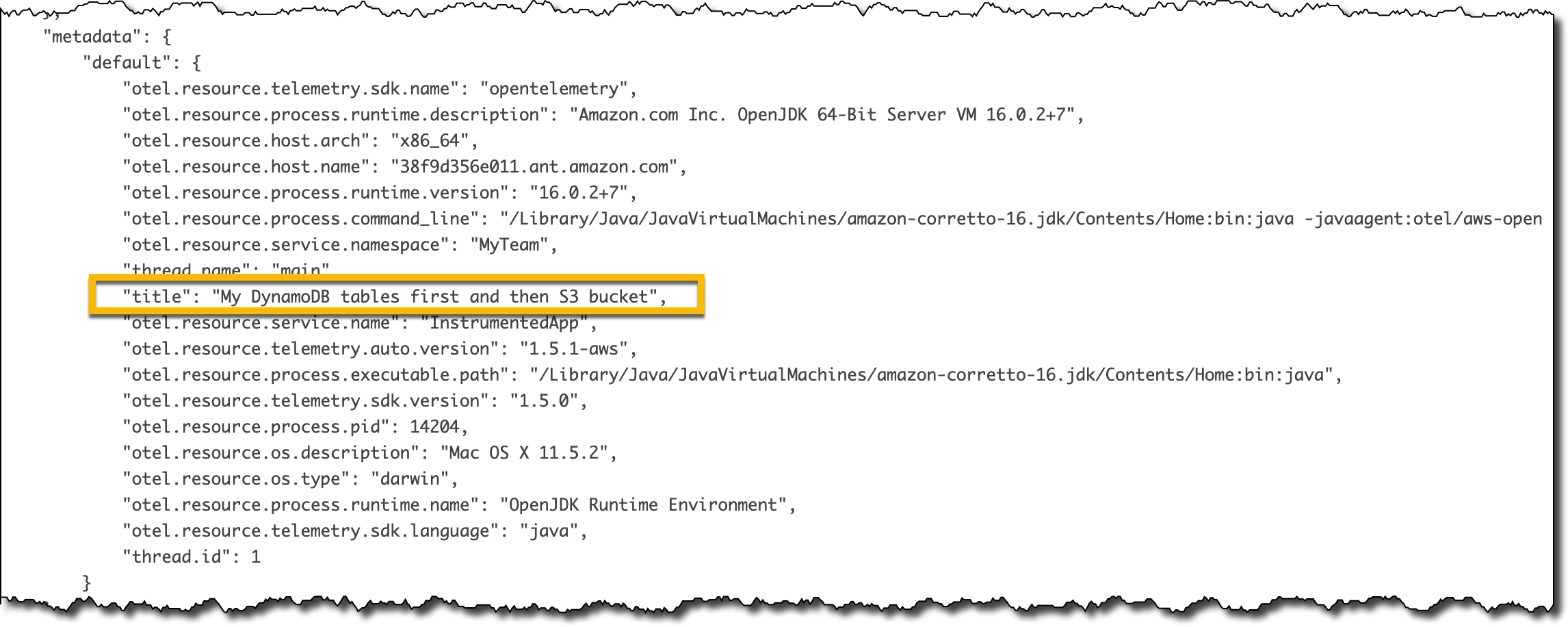
In the Traces section of the X-Ray console, I look at the Raw data for some of the traces. Because the title argument was annotated with @SpanAttribute, each trace has the value of that argument in the metadata section.
Collecting Traces from Lambda Functions
The previous steps work on premises, on EC2, and with applications running in containers. To collect traces and use auto-instrumentation with Lambda functions, you can use the AWS managed OpenTelemetry Lambda Layers (a few examples are included in the repository).
After you add the Lambda layer to your function, you can use the environment variable OPENTELEMETRY_COLLECTOR_CONFIG_FILE to pass your own configuration to the collector. More information on using AWS Distro for OpenTelemetry with AWS Lambda is available in the documentation.
Availability and Pricing
You can use AWS Distro for OpenTelemetry to get telemetry data from your application running on premises and on AWS. There are no additional costs for using AWS Distro for OpenTelemetry. Depending on your configuration, you might pay for the AWS services that are destinations for OpenTelemetry data, such as AWS X-Ray, Amazon CloudWatch, and Amazon Managed Service for Prometheus (AMP).
— Danilo
from AWS News Blog https://aws.amazon.com/blogs/aws/new-for-aws-distro-for-opentelemetry-tracing-support-is-now-generally-available/

